Some time back I had the pleasure of meeting some of the good folks at MapD. Among the topics we wound up talking about was Apache Arrow, an emerging in-memory columnar data representation with multiple language bindings which, to make a long story short, can let different analytics solutions pass data from one to another by reference, rather than by value. Very cool stuff, which dovetails with Remote DMA technology to allow a cluster to process big in-memory datasets with vastly more efficient communications for data interchange. So much pain and processing eliminated by just choosing a common (and well-optimized) representation and going with it.
I had previously encountered through work Jacques Nadeau, at MapR when I met him, and now a founder of Dremio, where the Arrow work was a byproduct of the development of Apache Drill and Dremio’s eponymous offering. And I said to Jacques when I crossed paths with him at Strata Hadoop World: “There will soon be two classes of analytics software: those that can interchange data with Arrow, and those that are obsolete.”
This blog post at kdnuggets on Arrow provides some good background.
Streamlining the interface between systems
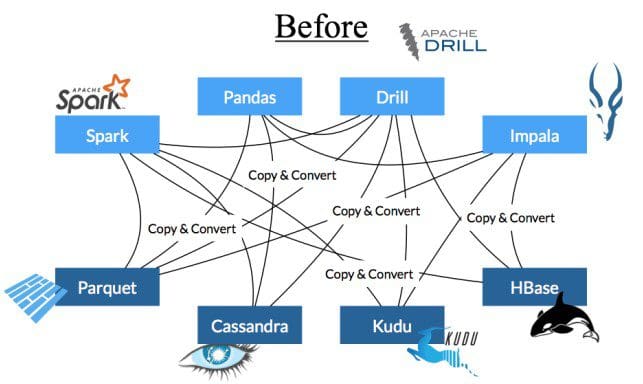
One of the funny things about computer science is that while there is a common set of resources – RAM, CPU, storage, network – each language has an entirely different way of interacting with those resources. When different programs need to interact – within and across languages – there are inefficiencies in the handoffs that can dominate the overall cost. This is a little bit like traveling in Europe before the Euro where you needed a different currency for each country, and by the end of the trip you could be sure you had lost a lot of money with all the exchanges!
We viewed these handoffs as the next obvious bottleneck for in-memory processing, and set out to work across a wide range of projects to develop a common set of interfaces that would remove unnecessary serialization and deserialization when marshalling data. Apache Arrow standardizes an efficient in-memory columnar representation that is the same as the wire representation. Today it includes first class bindings in over 13 projects, including Spark, Hadoop, R, Python/Pandas, and my company, Dremio.
Now I see MapD is taking up the use of Arrow and even driving the GPU Open Analytics Initiative, devoted to building out support for Arrow as part of making GPU analytics more performant and standard. From https://www.mapd.com/blog/2017/12/14/mapd-pandas-arrow/:
…While Spark has a python interface, the data interchange within PySpark is between the JVM-based dataframe implementation in the engine, and the Python data structures was a known source of sub-optimal performance and resource consumption. Here is a great write up by Brian Cutler on how Arrow made a significant jump in efficiency within pyspark.
MapD and Arrow
At MapD, we realize the value of Arrow on multiple fronts, and we are working to integrate it deeply within our own product. First, we are finding our place in data science workflows as a modern open-source SQL engine. Arrow solves precisely the problems we expect to encounter related to data interchange. Second, a natural outcome of being a GPU-native engine means that there is great interest in integrating MapD into Machine Learning where Arrow forms the foundation of the GPU dataframe, which provides a highly performant, low-overhead data interchange mechanism with tools like h2o.ai, TensorFlow, and others.
It’s so cool to see a good idea spreading and taking root. Hope I get to engage with Arrow (and with some of the cool people I’ve met over the years) soon.